
What is Learning?
Learning can be understood as the ability to incorporate new information and adapt to the environment. Whether it is a biological organism or an artificial system, learning allows us to adjust behaviors and decisions based on new stimuli or experiences.
Both humans and AI aim to achieve several key cognitive capabilities through learning. These objectives are central to both human cognition and artificial intelligence, guiding the way we classify, predict, generalize, solve problems, and adapt to new information or environments.
1. Classification: Recognizing and categorizing objects (e.g., knowing if an object is a cat or dog).
2. Prediction: Anticipating future outcomes based on current knowledge (e.g., predicting weather patterns or human behavior).
3. Generalization: Applying learned knowledge to new, unseen situations (e.g., understanding that a new breed of dog is still a dog).
4. Problem-Solving: Using learned information to solve novel tasks (e.g., solving a math problem or navigating a new route).
5. Adaptation: Adjusting behavior based on feedback and changing environments (e.g., adapting to new social norms or dynamic environments).
How Do Humans Learn?
Humans possess a unique ability to learn from their surroundings, from others, and from their own actions. This process can be divided into several types:
1. Innate Abilities: Some skills are encoded in our genetics. These abilities are present from birth and don’t require external learning. For instance, a newborn baby has reflexes, such as sucking or grasping, that are critical for survival.
2. Imitation Learning: A major way humans acquire skills is by observing and imitating others. Children learn to speak by mimicking the language spoken around them, and this type of learning continues throughout life in various forms, from social behaviors to technical skills.
3. Trial and Error: Another form of learning occurs when we set a goal and experiment with different actions until we reach that goal. This iterative process, driven by feedback, helps refine our behaviors and problem-solving abilities. For example, learning to ride a bike involves many trials and corrections before mastering balance and coordination.
4. Formal Learning: Formal education introduces structured learning through explicit rules and systems. For instance, learning grammar involves absorbing the rules that govern language use, much like how one might study mathematics or physics.
5. Abductive Learning: Learning by insight or deduction, making novel connections. Humans sometimes learn by sudden insight or deduction, where they connect pieces of information in a novel way. This isn’t quite trial and error or formal learning; it’s more of an intuitive leap.
In each of these modes, from imitation learning onwards, humans rely on System 2 thinking, a term coined by psychologist Daniel Kahneman, which involves deliberate and effortful cognitive processes. System 2 is activated when learning something new or challenging—such as studying or solving complex problems—whereas once we have mastered a skill, it shifts to the more automatic System 1, allowing us to perform the task with little conscious effort (e.g., driving or playing an instrument).
How Machines Learn
Machines, like humans, can learn in different ways. Machine learning, the core of artificial intelligence, involves algorithms that learn from data. The machine’s ability to improve its performance without being explicitly programmed for every task is what sets it apart from traditional programming. Below are some key types of machine learning:
1. Supervised Learning: In supervised learning, the machine is given labeled data. It “learns” by making predictions and comparing them to the actual outcomes. Over time, the algorithm adjusts its predictions to minimize errors.
• Example: Linear regression is one of the simplest forms of supervised learning. The machine learns to draw a line that best fits the data points, predicting future outcomes based on this learned model.
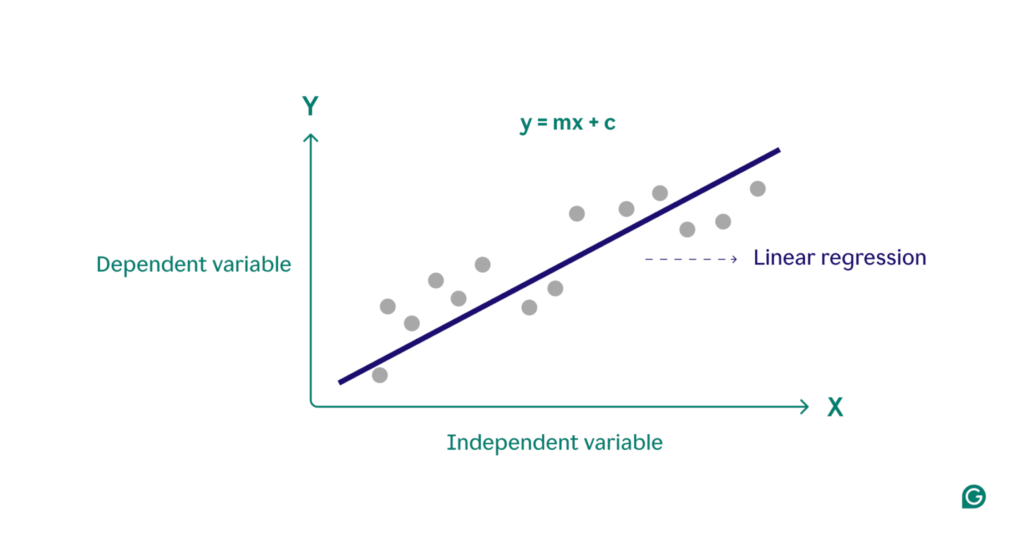
The main limitation of supervised learning is that we need a lot of labelled data that the system can learn from.
2. Unsupervised Learning: Here, the machine is not provided with labeled data. Instead, it identifies patterns and structures within the data. This can be compared to a child observing their environment and identifying patterns without explicit instruction.
• Example: Clustering algorithms (e.g., k-means) can group data points that are similar to one another, much like how a child might notice similarities in objects or behaviors without being told.
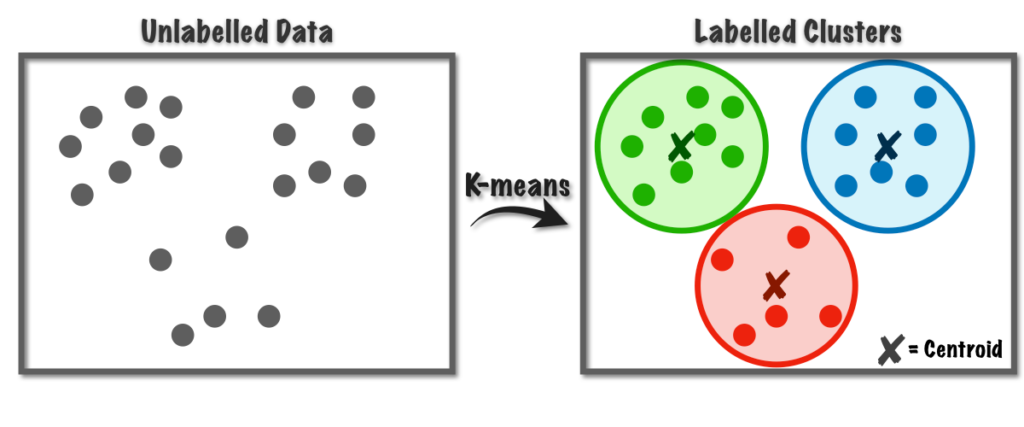
The main advantage of unsupervised learning is that it can work without labeled data, making it valuable for tasks like clustering and pattern discovery. However, its primary limitation is that it is applicable to a more limited set of problems compared to supervised learning, and the results can be harder to interpret or validate.
3. Self-Supervised Learning: Self-supervised learning occupies a middle ground between supervised and unsupervised learning. In self-supervised learning, the machine generates its own labels from the input data. It doesn’t rely on external labeled data (as in supervised learning), but instead, it finds patterns and relationships within the data itself to create tasks that guide learning.
• Example: Modern language models, such as those used for generating text, often use self-supervised learning to predict missing words in a sentence. Given a piece of text with some words removed, the model learns to fill in the blanks based on the context. Over time, this helps the model improve its understanding of language structure, meaning, and context. This approach mimics human learning, where we often learn through trial and error, refining our understanding based on feedback from the environment.
• Another example: Diffusion Models: Recently, diffusion models have emerged as a powerful application of self-supervised learning, particularly in generating images. In diffusion models, the system learns to progressively transform random noise into a coherent image, essentially learning to reverse the process of noise addition. This involves self-supervised learning because the model is trained to predict and reduce the noise at each step, gradually generating clear images from what starts as noise.
The main advantage of this method is that it enables the use of massive datasets without requiring the time-consuming and expensive process of manual labeling. As AI models grow in size and complexity, self-supervised learning allows them to extract meaningful insights from data on their own, greatly enhancing their ability to generalize and perform complex tasks without relying solely on human input.
4. Imitation Learning: Learning by observing and mimicking expert behavior or demonstrations.
Imitation learning has become increasingly important, especially in environments where rewards for correct behavior are rare or difficult to define—often referred to as sparse reward settings. In these situations, AI systems can struggle to learn effectively because they receive very little feedback or “rewards” for taking the right action.
• Sparse Reward Settings: Imagine a scenario like teaching a robot to navigate a complex environment. In sparse reward settings, the robot might only receive feedback when it reaches the end of the course, but until then, it doesn’t know whether it’s on the right track or making mistakes. This is where imitation learning excels.
Imitation learning allows the AI to observe and mimic human experts or other trained systems, learning from examples of correct behavior rather than relying on occasional rewards or penalties. This has proven to be especially effective in real-world tasks such as self-driving cars and robots navigating general environments. In these cases, AI systems must make many decisions continuously, and it’s inefficient to wait for rare rewards to guide learning. Instead, by observing how humans drive or move through space, the AI learns directly from demonstrated behavior.
• Example: A self-driving car doesn’t need to be programmed with countless rules or to learn entirely through trial and error (which would be unsafe). Instead, it can observe expert human drivers and imitate their actions—learning how to navigate roads, avoid obstacles, and follow traffic laws from the very start.
Until recently, it was believed that rule-based systems or, in some cases, reinforcement learning (described below) would be the primary methods for teaching AIs to operate in complex environments. However, imitation learning has proven to be more efficient and effective in many of these cases. It allows AI to rapidly learn from vast amounts of examples and then generalize to new situations, often outperforming systems that rely on rules or trial-and-error learning.
Why Imitation Learning is Key: In fields like robotics, gaming, or autonomous vehicles, where direct feedback (rewards or penalties) may be delayed or rare, imitation learning provides a shortcut. It taps into the expert knowledge of humans and other systems, helping AI learn more efficiently in environments where traditional methods would take much longer or even fail to achieve success.
5. Reinforcement Learning: Learning through interaction with an environment, using feedback in the form of rewards and penalties to improve decision-making over time.
This is the kind of learning that closely resembles the interaction how living creatures in their environment. Creatures are moved by goals (for example eat, not die, reproduce, and others), they are equipped with understanding of their environment and are able to make some predictions, and they act accordingly, receiving feedback.
This kind of learning is powerful, but has one main limitation: it works well in situations where feedbacks are frequent, for example in a chessboard play. In general life situations, which include also specific activities like driving a car, a system that should learn “by itself” just by trial and errors, would probably fail do do so effectively, or require an tremendous amount of time or iterations.
This is why, we found out that a better way to handle this kind of learning how to behave in sparse reward situations is in fact imitation learning, after that reinforcement learning can kick in to allow even better and fine tuned actions.
• Example: AI agents learn to play video games or solve real-world tasks by adjusting their actions based on rewards (e.g., completing a level) or penalties (e.g., failing a task). This method allows the AI to optimize its actions based on outcomes. Also for video-games we learned that, especially for sparse reward situations, the best learning path followed imitation learning (learn from how for example, humans play) and than take it from here.
Reinforcement Learning with Human Feedback (RLHF):
An area where reinforcement learning is applied is also the fine tuning of modern generative AI models. The technique is called “Reinforcement Learning with Human Feedback”. After a model has trained “by itself” using a self-supervised learning approach, its behaviours are ranked by humans. This will train a reward model, which is basically an AI that will be able to judge the subsequent behaviours of the model and assign it rewards and penalties.
This process is surprisingly similar to how formal education is applied in human learning. For example, children learn basic behaviors and skills, often through imitation and trial and error, before formal education or rules are introduced. Much like RLHF fine-tunes AI models, formal education in humans serves to refine previously learned behaviors, aligning them with societal norms, moral values, and cultural expectations.
What are we learning from the engineering of powerful AIs that we could apply to human cognition?
Avoid Overfitting in Human Learning
• AI Insight: In machine learning, overfitting occurs when models become overly complex and focus too much on the specific training data, losing their ability to generalize to new, unseen situations. This can happen when models are trained on too little or too specific data, making them fail to predict broader trends.
• Human Learning Application: Similarly, humans can fall into the trap of “overfitting” in learning. When people over-specialize or repeatedly train on the same experiences, they may struggle to adapt to new situations or think creatively. For instance, a student who memorizes facts for exams without understanding broader concepts may struggle to apply that knowledge in real-world scenarios.
• Solution: Just as diverse training data prevents overfitting in AI, humans benefit from diverse experiences and exposure to multiple perspectives. Encouraging interdisciplinary learning, problem-solving in unfamiliar environments, or engaging with people from different backgrounds helps build more flexible, adaptable intelligence. Simplicity, as seen in linear regression, often proves effective in predicting future trends, so focusing on clear, fundamental principles might sometimes work better than over-complicating knowledge structures.
• Example: When learning to solve a complex problem like designing a product, someone who has studied different fields (e.g., engineering, psychology, and business) can often make better predictions and decisions than someone who has specialized only in one area.
Model Distillation: Human Cognition as Generational Knowledge Transfer
• AI Insight: Model distillation is a process where a large, complex model transfers its knowledge to a smaller, more efficient model, enabling it to retain essential knowledge without all the complexities of the original.
• Human Learning Application: This mirrors how cultural and generational knowledge is passed down to younger generations. Human societies distill the experiences and lessons of the past into simpler, more digestible forms—through teaching, storytelling, or written records—so that new generations don’t need to relive all historical experiences to benefit from their knowledge.
• Example: The way history is taught in schools is a form of “knowledge distillation.” Instead of requiring students to read every historical document ever written, they receive a distilled, contextualized understanding of key events and themes that help them make sense of the past and inform future decisions.
• Additional Thought: This concept could be applied more actively in human learning by encouraging mentorship and interdisciplinary collaboration. We should focus on making complex knowledge more accessible to learners, not by overwhelming them with data but by distilling the essential insights and principles from a vast body of work.
Imitation vs. Rule-Based Learning
• AI Insight: AI systems, particularly deep learning models, have demonstrated the ability to learn more effectively through imitation learning (observing examples) than through rigid, rule-based systems. This is especially valuable in environments where outcomes are uncertain or rewards are sparse—like autonomous driving, where trial-and-error is inefficient or unsafe.
• Human Learning Application: In human learning, imitation is fundamental, especially in early development, where children learn by observing their parents, teachers, and peers. Modern AI’s success in imitation learning reinforces the importance of role models and learning by example in human development.
• Example: Think of a child learning to communicate. Language learning doesn’t happen through a set of rules laid out step by step; instead, children observe and imitate speech patterns, gestures, and facial expressions from those around them. Later, they learn formal grammar rules, but imitation plays a much larger initial role in their learning process.
• Additional Thought: This highlights the importance of good role models in human learning. Just as AIs trained with poor-quality data can learn harmful or incorrect patterns, humans need access to high-quality, ethical, and nuanced models to imitate. This could be applied in education, where interactive, example-based learning can often be more effective than rule-based instruction.
Reinforcement Learning for Human Decision-Making
• AI Insight: In AI, reinforcement learning involves learning by interacting with an environment, receiving feedback in the form of rewards or penalties, and adjusting actions accordingly. This has been critical in AI systems mastering games, robotics, and autonomous control systems.
• Human Learning Application: Humans also learn through reinforcement, especially in environments where immediate feedback is provided, such as sports, social interactions, or professional development. Humans can optimize their behaviors over time by receiving feedback (e.g., praise, criticism, rewards) and adjusting accordingly.
• Example: A salesperson learns which techniques work best by interacting with customers. They may receive positive reinforcement in the form of successful deals and adjust their approach based on what earns rewards (e.g., a closed sale).
• Additional Thought: Reinforcement learning in humans can be enhanced by providing more structured feedback and creating environments where failure is seen as a learning opportunity rather than a setback. This “growth mindset” approach encourages people to experiment and iterate, similar to how reinforcement learning agents optimize their actions over time.
Key points to remember:
1. Learning as Adaptation: In both humans and machines, learning involves adapting to new information and experiences to improve decision-making and behavior over time.
2. Human Learning Methods: Humans learn through multiple approaches—innate abilities, imitation, trial and error, formal education, and abductive insights. Each plays a vital role in acquiring and refining knowledge.
3. Machine Learning Approaches: Machines learn through supervised, unsupervised, self-supervised, reinforcement, and imitation learning, each suited to different types of tasks and data.
4. Avoiding Overfitting in Human Learning: Just like AI models, humans risk “overfitting” when focusing too much on specific experiences. Diverse experiences and exposure to multiple perspectives lead to better generalization and adaptability.
5. Imitation and Role Models: Imitation learning is powerful for both humans and AI. High-quality examples and role models are essential for effective learning, as poor inputs can lead to harmful patterns.
Exercises for Applying Human and Machine Learning Concepts
1. Explore Diverse Methods: Follow a simple recipe (e.g., making a sandwich) by reading instructions first, then watching a video tutorial. Reflect on how each method influences your understanding and execution.
2. Imitate vs. Follow Rules: Try completing a task (e.g., building a model) by first following written instructions, then by imitating an expert. Compare the results and reflect on which method felt more effective.
3. Distill Knowledge: Take a complex topic you know well and explain it in simple terms to someone unfamiliar. Focus on distilling the core concepts without losing meaning.
4. Trial and Error Learning: Choose a real-world problem to solve (e.g., organizing a space) and use trial-and-error to improve your approach. Record the feedback you get and refine your strategy.
5. Reflect on Role Models: Identify someone whose behavior or skills you’ve learned by imitation. Write down how they’ve influenced your learning and decision-making.
1. “Thinking, Fast and Slow” by Daniel Kahneman – This book explores the two systems of thinking—System 1 (fast, intuitive) and System 2 (slow, deliberate)—and provides insights into how humans make decisions and learn.
2. “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville – A comprehensive introduction to deep learning and machine learning, explaining the principles behind various learning methods, including supervised, unsupervised, and reinforcement learning.
So Far…
- We’ve understood that competence can exist without comprehension. Both humans and AI systems can perform tasks effectively without being aware of them (chapter 1)
- Learning is multifaceted, encompassing for AIs, unsupervised, supervised, self-supervised, imitation, and reinforcement learning techniques. These categories, born in the AI field, can also be applied to describe learning in humans, even if for humans we prefer to use different categories like experience, formal education and others. (chapter 2)
- Self-supervised and imitation learning proved to be very effective for AIs: for example to create intelligent chatbots like Chat GPTs or self-driving cars. After this initial training we usually “polish” their intelligence applying a formal education that we call “alignment”, this is a pattern that closely matches the process of learning for humans as well. (chapter 2)
Looking Ahead: Evolution
The journey towards more advanced AI systems has involved significant evolution in learning approaches and understanding. In the next chapter, we will explore the progression that led to where we are today, considering how both human and artificial minds have evolved over time.